


Este es el primero de una serie de tutoriales básicos sobre zOS. La idea es ayudar a aquellas personas que empiezan en Mainframe a entender algunos conceptos que serán la base de otros conocimientos más complejos. Está entrada se centra en TSO e ISPF.
NOTA: Las imágenes que hay en la entrada son de un sistema básico. Según el sistema en el que trabajemos, puede haber otras opciones adicionales o estar ubicadas en otro panel, pero las que vamos a conocer aquí son comunes a todos los sistemas.
TSO (Time Sharing Options) es una aplicación que permite interactuar con el sistema. La mayoría del tiempo que trabajemos en Mainframe usaremos está aplicación. Cuando entramos a TSO, tendremos que poner el usuario que nos hayan proporcionado.
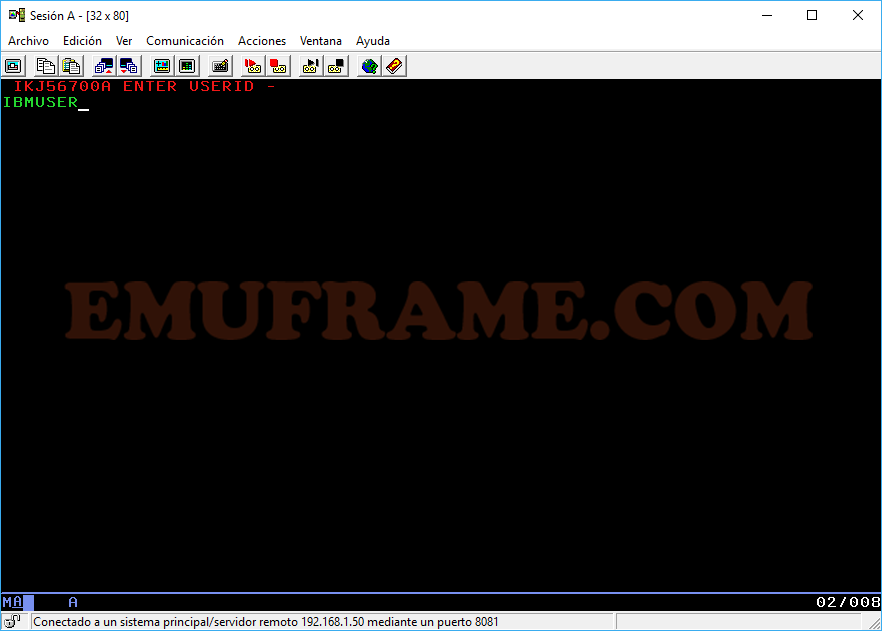
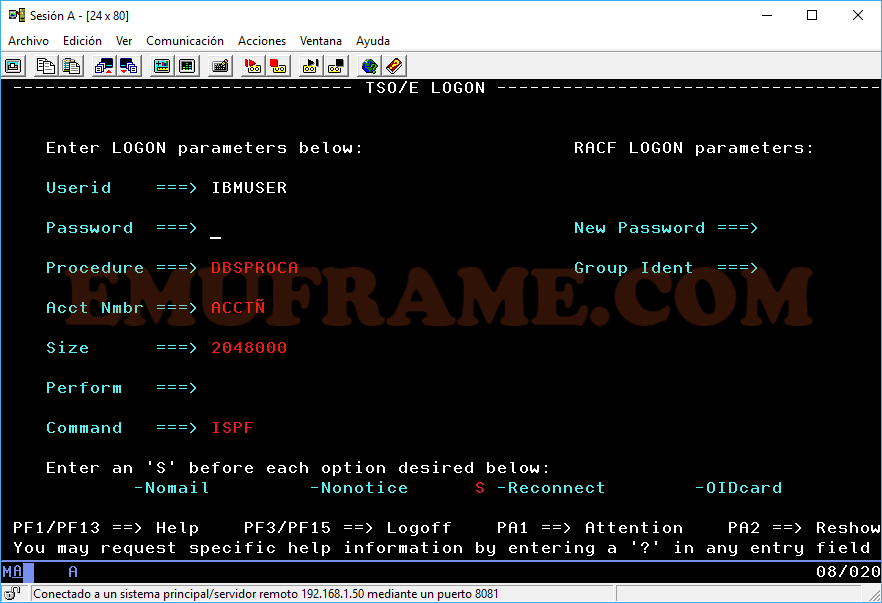
Cuando pulsemos Intro (o la tecla control), nos aparecerá una pantalla donde deberemos poner la contraseña (Password) o cambiar la contraseña, si fuese necesario (New Password).
El resto de parámetros deberán rellenarse de forma automática.
Al final del panel vemos varias opciones: Nomail, Nonotice, Reconnect, OIDcard. Lo más habitual es tener marcada, con “S”, la opción Reconnect. Cuando nos salimos mal de TSO, nuestro usuario seguirá en ejecución un tiempo y al volver a logarnos, nos dirá que el usuario está en uso. Marcando la opción Reconnect, podremos recuperar nuestra sesión, aunque no funciona siempre. En caso de no poder recuperar la sesión, tendremos que esperar a que caduque o pedir a alguien que tenga permisos que cancele nuestro usuario.
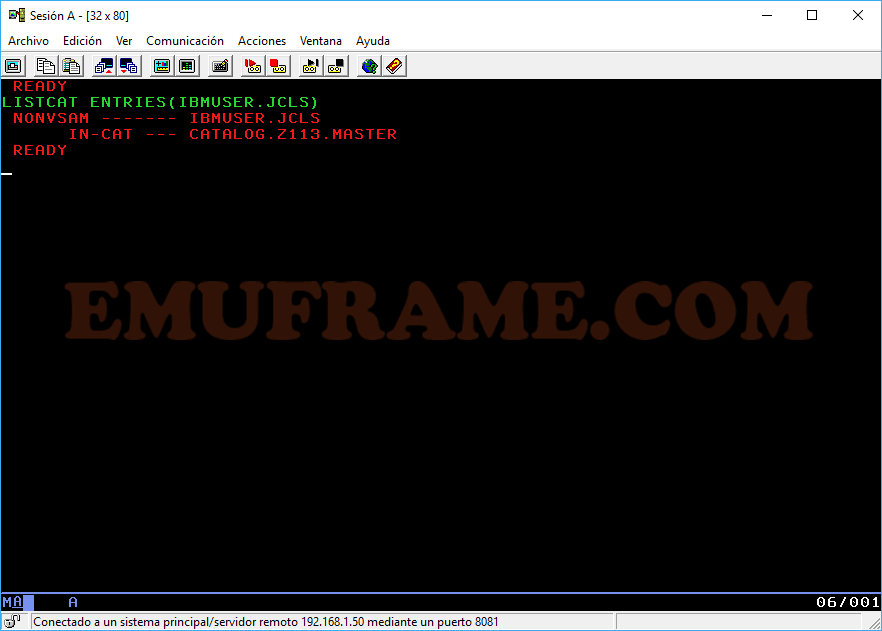
La comunicación de TSO con el sistema se hace mediante comandos, pero en sesiones interactivas esto no se suele usar. Un ejemplo de un comando de TSO es el siguiente:
Normalmente trabajaremos con una interfaz de menús llamada ISPF (Interactive System Productivity Facility). De esta forma podremos usar TSO sin necesidad de dar comandos.
Un menú de ISPF común podría ser similar al de la siguiente imagen.
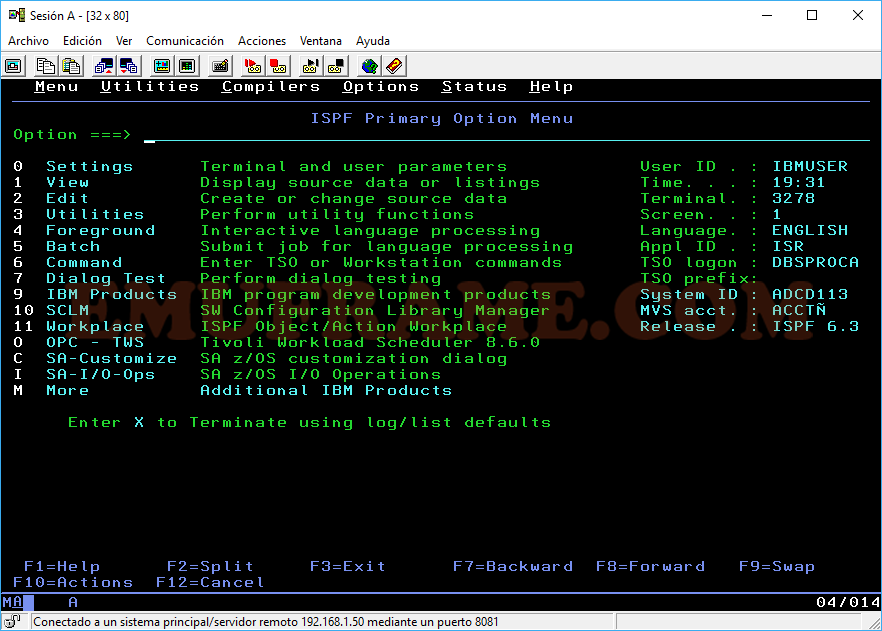
Algunas de las opciones que se suelen usar son: Settings, View, Edit, Utilities y Command.
Empezaremos viendo la opción Settings. Accederemos poniendo “0” o “Settings”.
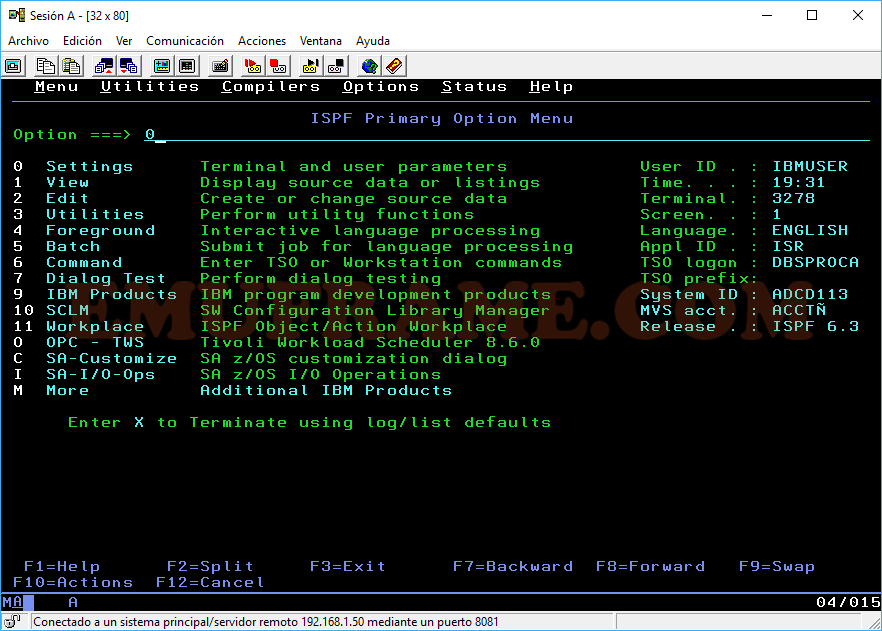
Aquí configuraremos algunos de los parámetros de nuestra sesión. Yo suelo quitar las siguientes opciones:
- Command line at bottom. Esto hace que tengamos la línea de comandos en la parte de abajo. En mi caso, prefiero trabajar con ella arriba.
- Tab to action bar choices. Cuando tenemos el cursor en cualquier parte del panel y pulsamos la tecla “Inicio”, se posicionará en la parte superior del panel. Si desmarcamos esta opción y pulsamos Inicio, el cursor irá directamente a la línea de comandos.
- Always show split line. Cuando partimos la pantalla pulsando F2 (split), se mostrará una línea que indica que la pantalla esta partida. Desmarcando esta opción, la quitamos.
El resto de opciones las suelo mantener por defecto.
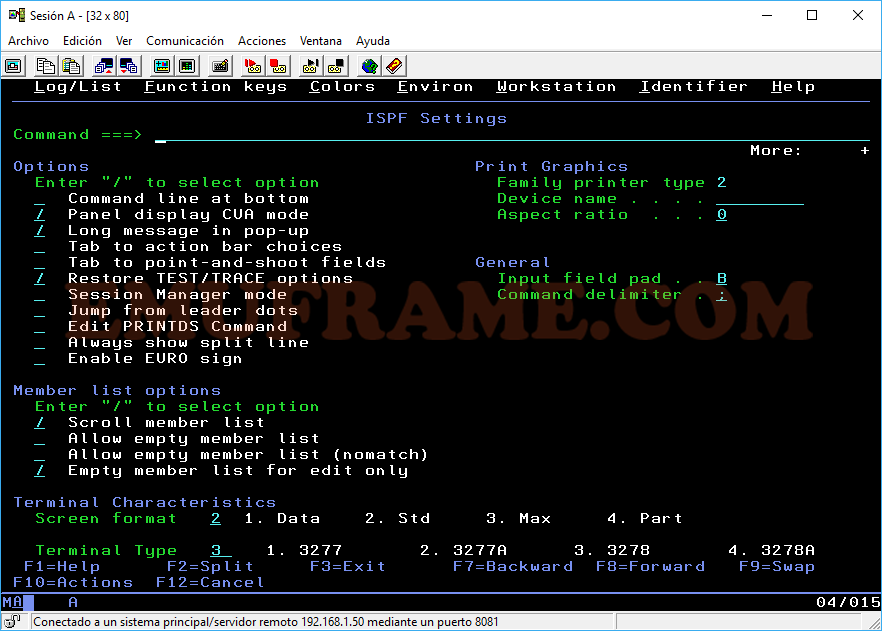
Si posicionamos el cursor en la parte superior del panel, concretamente donde pone “Function keys”, y pulsamos Intro, aparecerá un panel con distintas opciones para modificar la lista de las teclas de función (F1, F2, F3…). En mi caso, suelo desactivar la opción “Keylist” para que use las teclas por defecto ya que son más útiles. Para desactivarlo, elegiremos la opción 9.
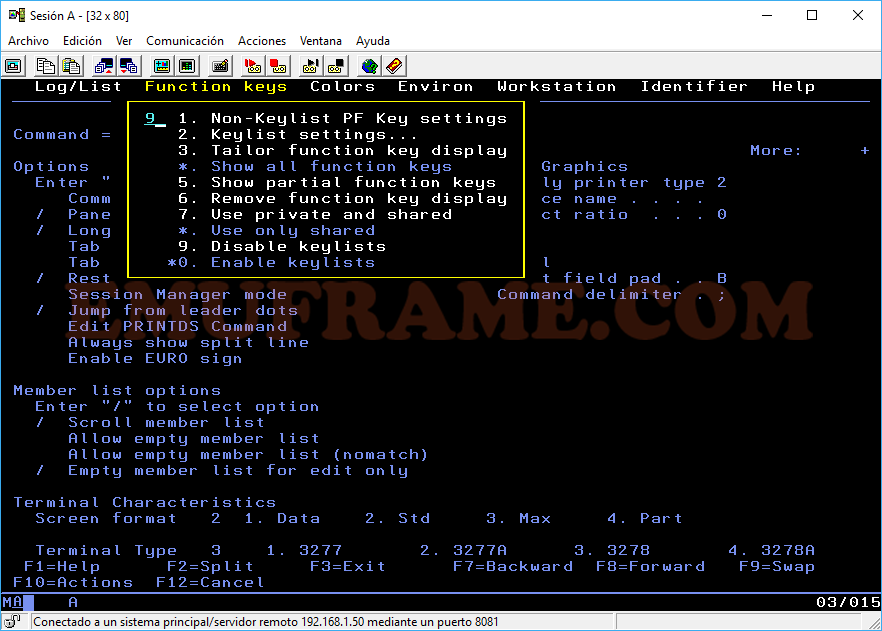
Veremos, en la parte de abajo, que la lista ha cambiado. Si nos fijamos en la tecla F12, vemos que antes ponía “Cancel” y ahora “RETRIEVE”. Esta opción nos permitirá repetir los últimos comandos que hayamos dado. Si pulsamos una vez F12, saldrá el último comando dado, si volvemos a pulsar F12, saldrá el anterior y así.
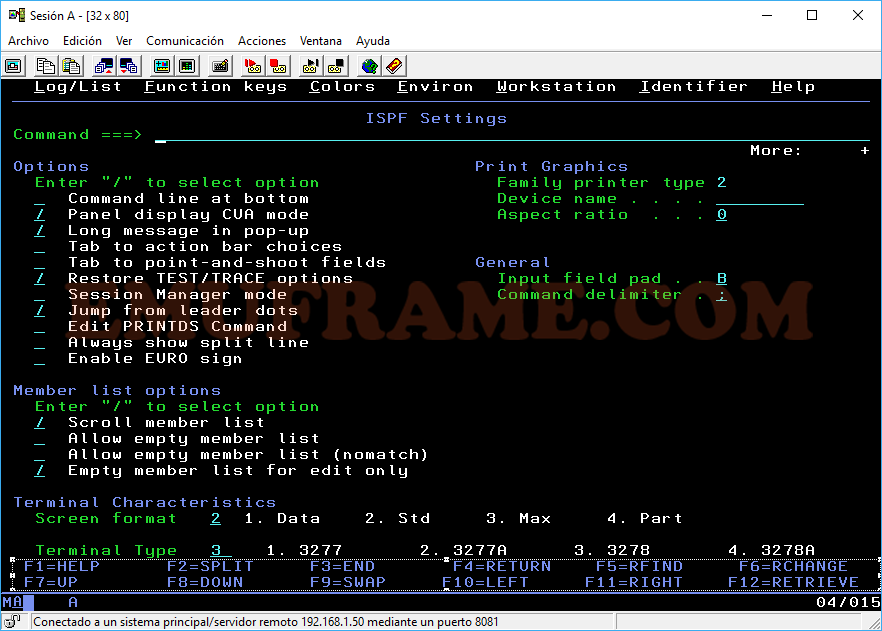
Después de un tiempo trabajando con esta lista de teclas de función, ya nos habremos aprendido lo que hace cada una, por lo tanto, podemos hacer que no se muestre. Para ello, usaremos el comando “PFSHOW OFF”. Si queremos que se muestren de nuevo, pondremos “PFSHOW ON”.
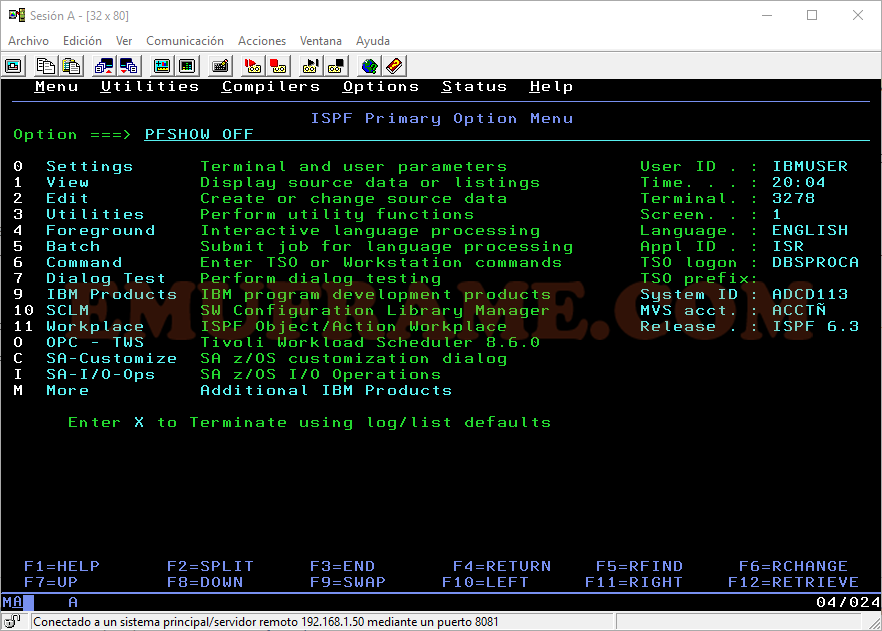
Ahora vamos a la opción View. Esta opción permite acceder a datasets secuenciales y a miembros de datasets particionados para ver su contenido, sin poder guardar la modificación. En una entrada posterior, explicaré los tipos de datasets y cómo crearlos. Entramos en la opción poniendo un “1”.
Lo más interesante de esta opción es que nos permite acceder directamente a un miembro de un dataset particionado, usando la notación nombre_dataset(nombre_miembro), por ejemplo:
IBMUSER.JCLS(RECEIVEJ)
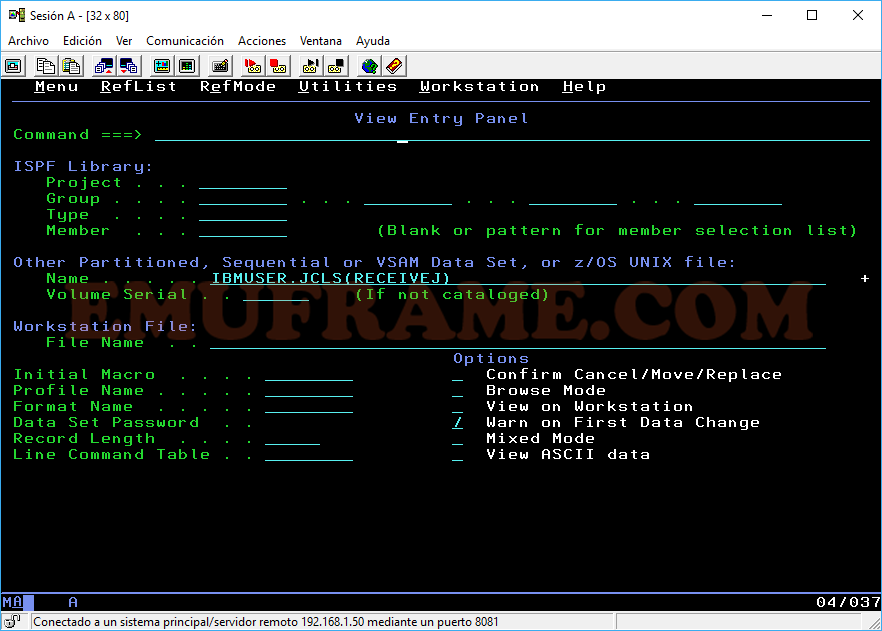
Si al pulsar Intro, nos aparece el mensaje “Data set not cataloged”, pero sabemos que existe, es porque nos está añadiendo un prefijo al nombre del dataset. Este prefijo suele ser nuestro usuario. Para solucionarlo podemos poner el nombre del dataset entre comillas simples:
‘IBMUSER.JCLS(RECEIVEJ)’.
Para no tener que poner las comillas todo el rato, podemos usar el comando “TSO PROFILE NOPREFIX” para evitar que nos añada el prefijo.
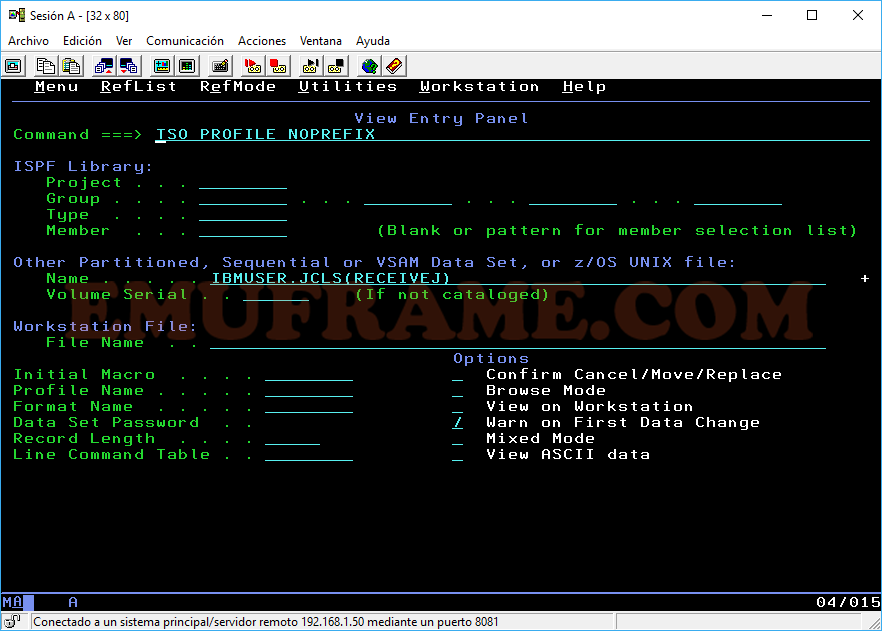
Ya podremos acceder en modo “VIEW” al fichero deseado.
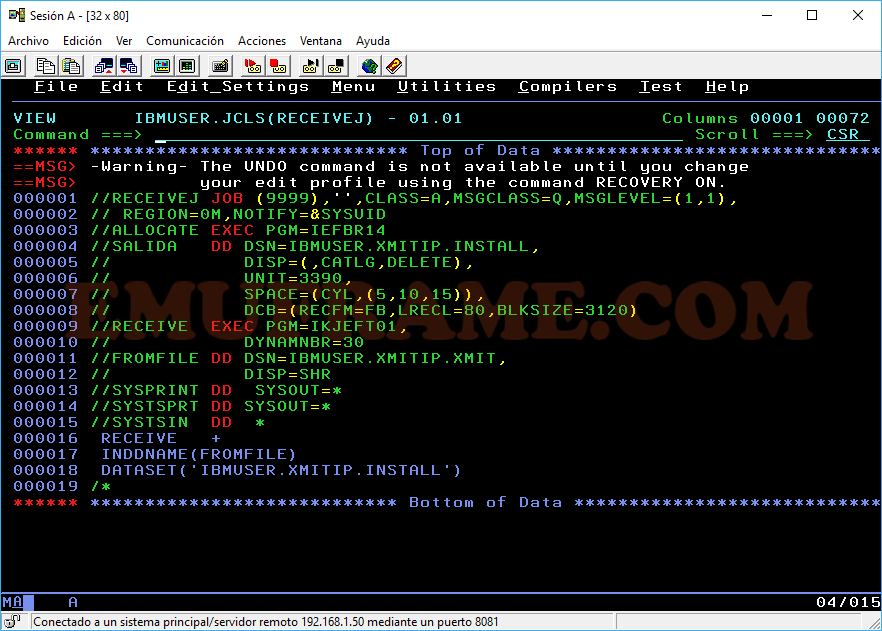
Salimos con F3, hasta llegar al panel principal de ISPF y entramos en la opción 2 – Edit.
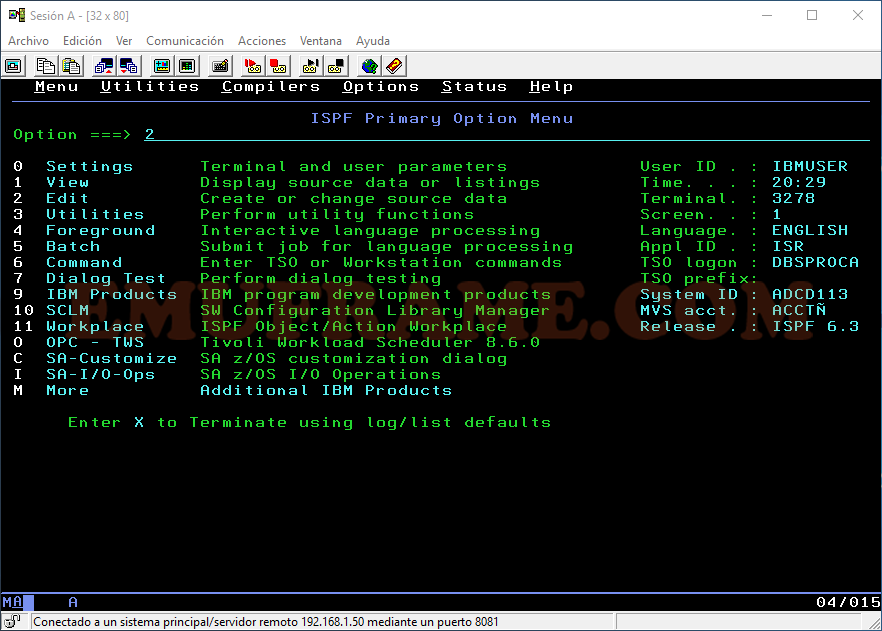
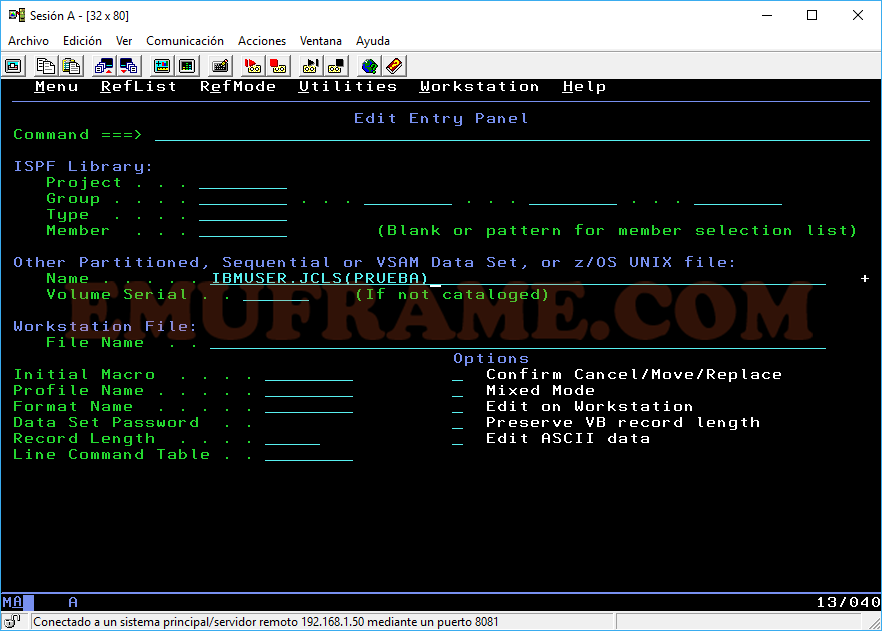
Esta opción es similar a la opción View, pero aquí si nos permitirá modificar el fichero deseado o crear un nuevo miembro de un dataset particionado, en caso de que no exista.
Si ponemos el nombre de un miembro que no exista en el dataset IBMUSER.JCLS, aparecerá de la siguiente forma.
Vemos que no tiene ningún contenido. Además, si nos fijamos en la izquierda, donde debería aparecer la numeración de las líneas, aparecen seis puntos en rojo.
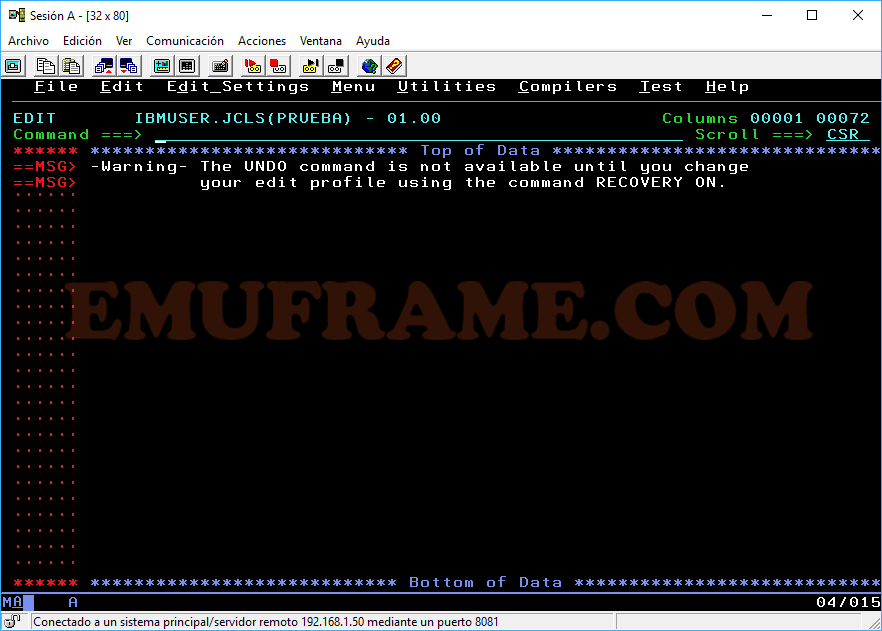
Escribiremos una línea de prueba y pulsaremos Intro. Después escribiremos “SAVE”, para guardarlo.
NOTA: Si salimos con F3, también se guardarán los cambios. Para que no se guarden, debemos escribir CANCEL.
Aparecerá un mensaje indicando que ha sido guardado.
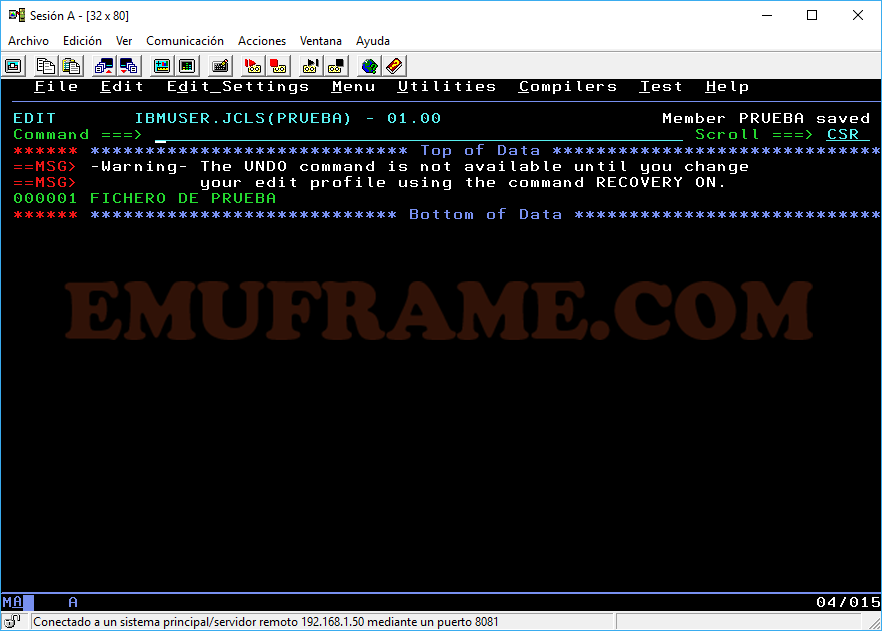
La próxima vez que accedemos, ya veremos que tiene el contenido con el que lo hemos guardado.
Desde el panel principal de ISPF, entraremos a la opción 3 – Utilities.
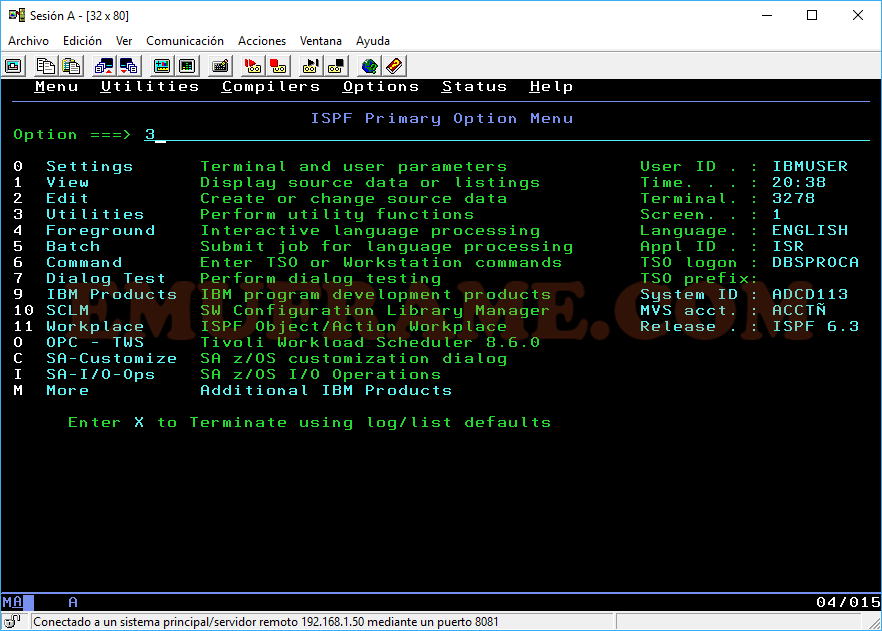
Veremos las siguientes opciones. La opción más habitual es la opción 4 – Dslist. Otras opciones pueden ser la opción 2 para crear dataset o la opción 3 para copiar miembros o datasets completos.
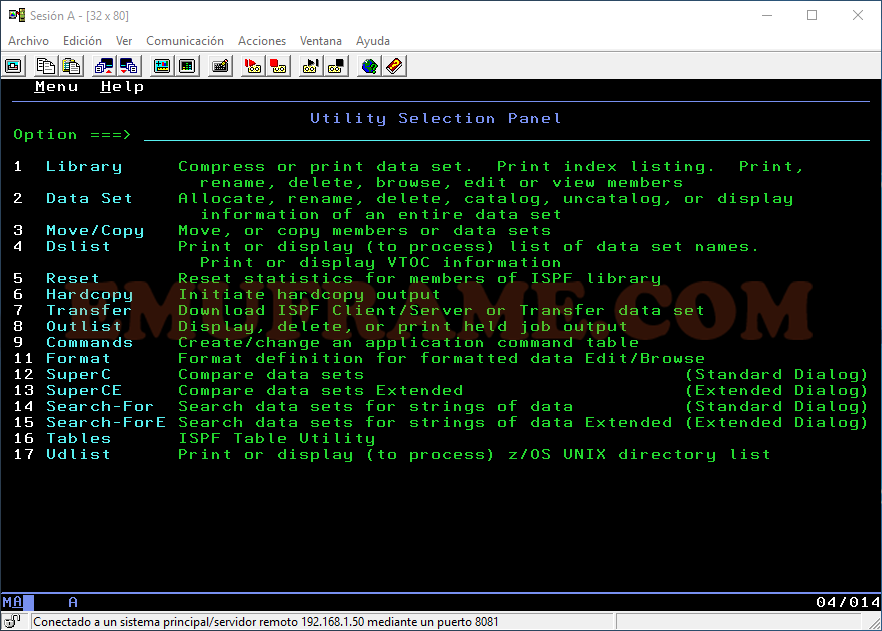
En esta entrada nos vamos a centrar sólo en la opción 4. Las otras dos opciones las veremos cuando hablemos de los tipos de datasets.
La opción 4 permite buscar datasets que existen y estén catalogados o buscar datasets directamente en el disco donde se encuentran. La opción del disco se suele usar para aquellos datasets que existen, pero no están en el catálogo (esto lo explicaré cuando hablemos de los tipos de dataset y cómo crearlos).
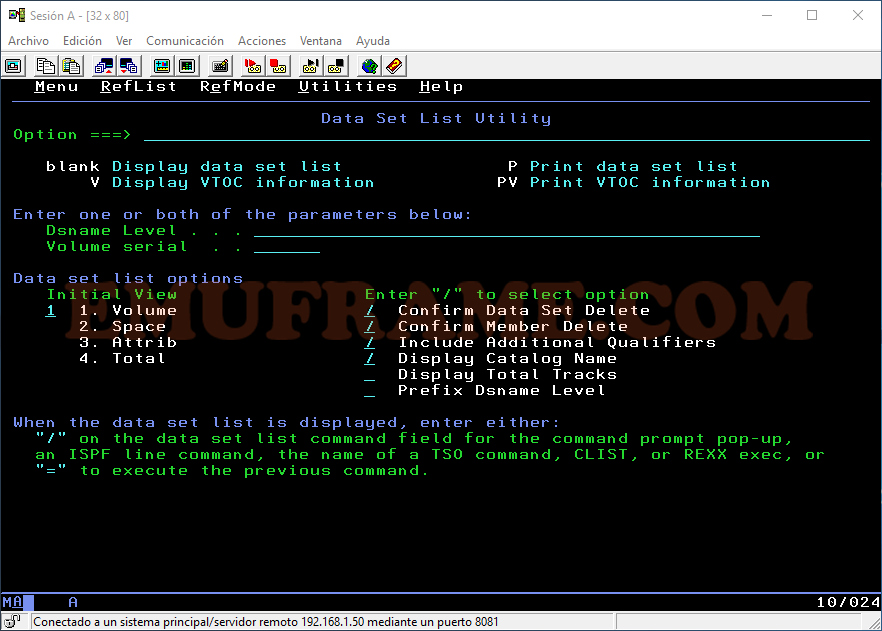
Para buscar datasets, simplemente pondremos el nombre completo o parte del nombre. Si queremos buscar los datasets que empiezen por “IBMUSER”, lo pondremos como se ve en la imagen y pulsaremos Intro.
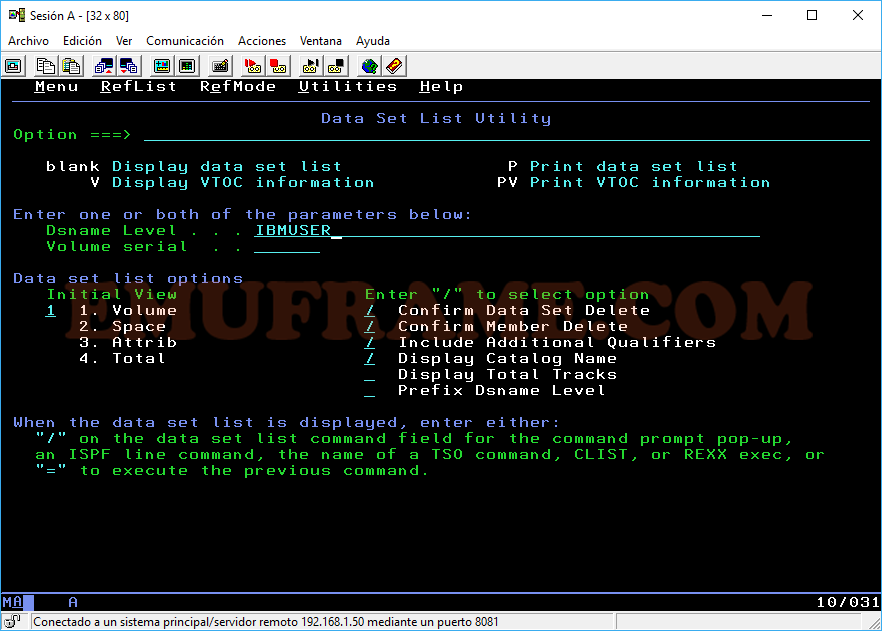
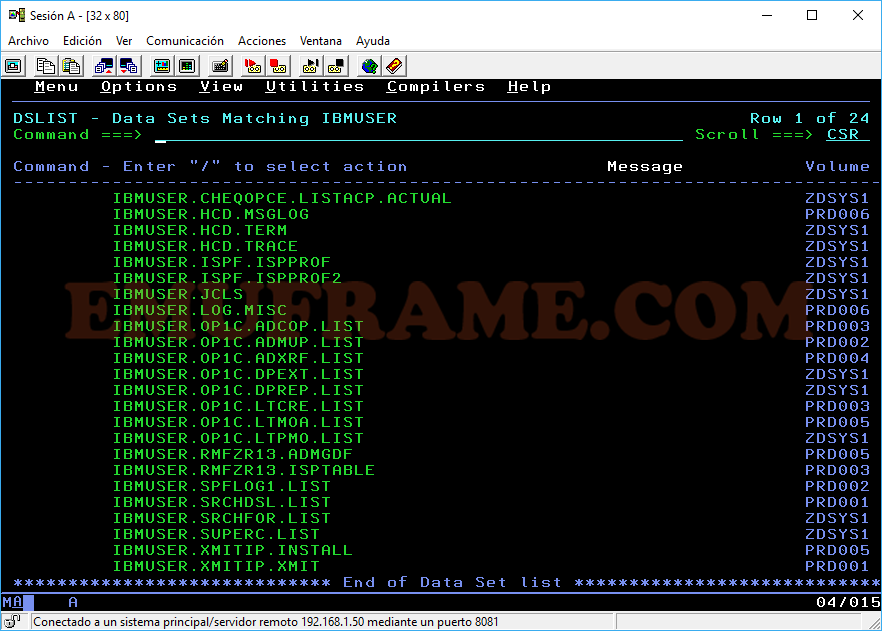
Vemos que sale un listado de datasets que empiezan por IBMUSER.
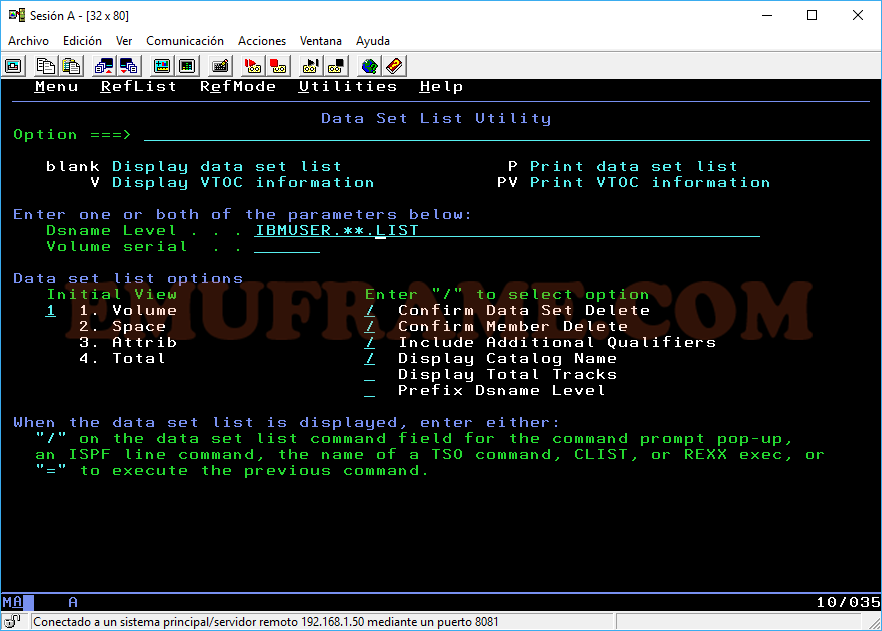
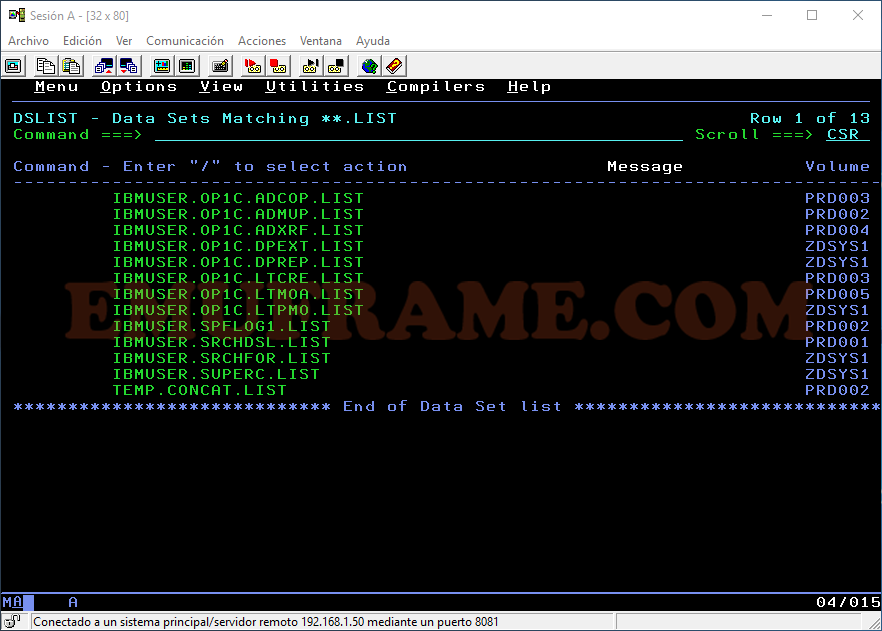
La búsqueda también permite el uso de asteriscos. Por ejemplo, si queremos buscar todos aquellos datasets que empiecen por IBMUSER y terminen por LIST, lo pondremos tal y como se ve en la imagen.
Vemos que aparecen datasets que empiezan por IBMUSER y terminan por LIST. Cuando ponemos dos asteriscos en la búsqueda, quiere decir que puede tener varios calificadores entre medias en el nombre (cada calificador está sepadado por un punto). Por ejemplo:
IBMUSER.OP1C.ADCOP.LIST -> Tiene dos calificadores “OP1C.ADCOP”.
IBMUSER.SPFLOG1.LIST -> Sólo tiene un calificador entre IBMUSER y LIST, que es “SPFLOG1”.
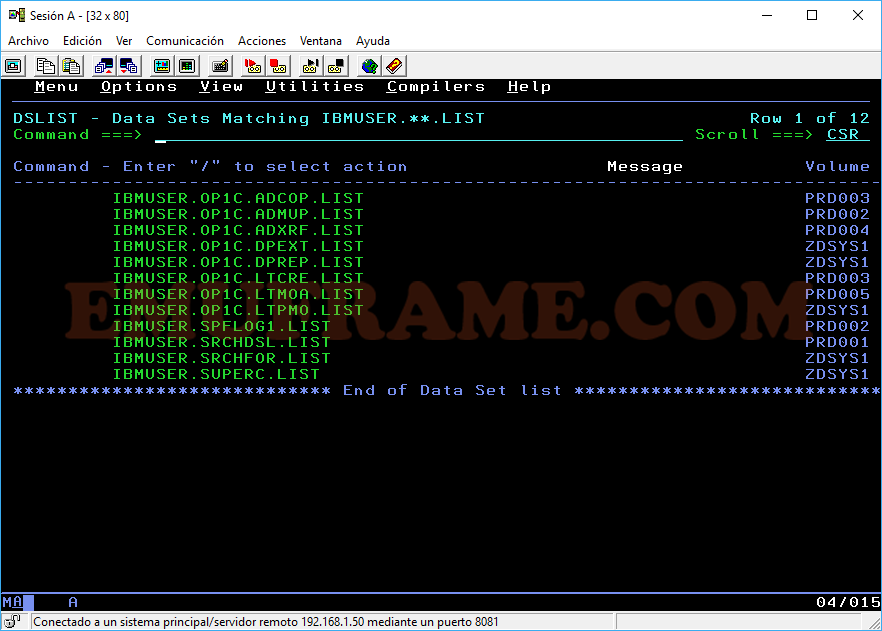
Vamos a hacer la búsqueda poniendo sólo un asterisco.
Vemos que aparecen datasets con un calificador entre IBMUSER y LIST.
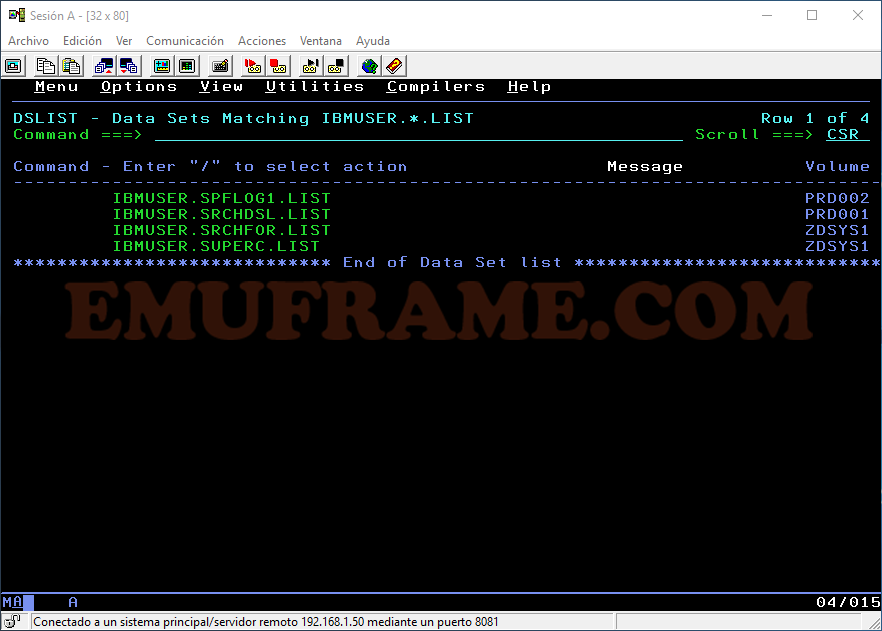
Imaginemos que sólo sabemos el final del nombre de un dataset, pero no sabemos cómo empieza. Podemos buscarlo poniendo dos asterisco al principio del nombre.
NOTA: Hay que tener cuidado con este tipo de búsquedas ya que buscan en todo el catalogo y puede consumir bastante máquina.
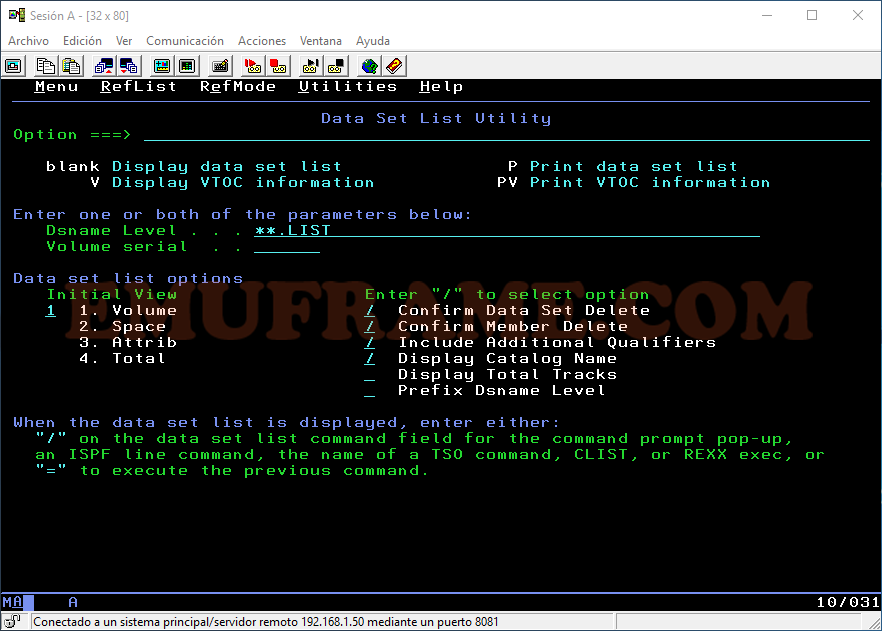
Saldrá un mensaje indicando que se va a buscar en todo el catálogo.
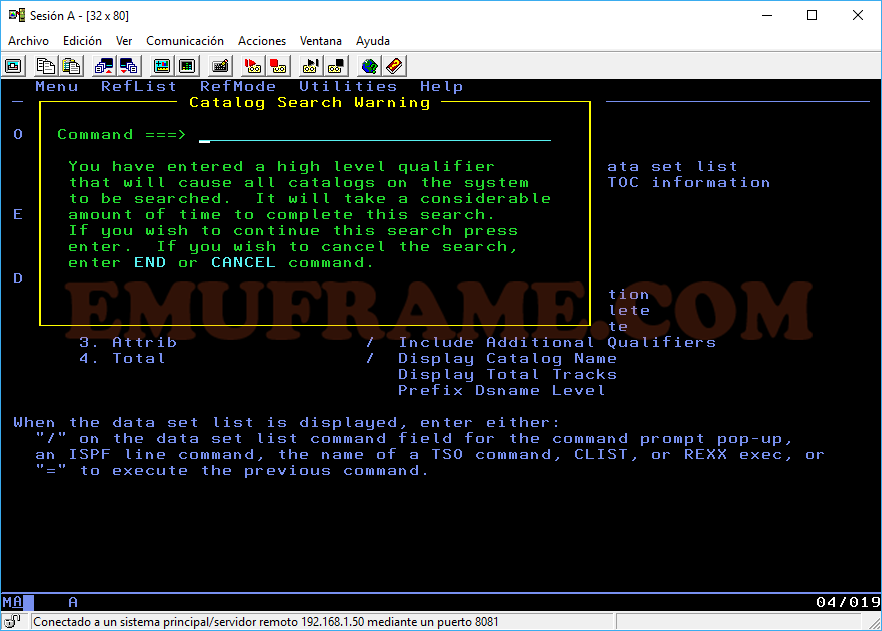
Finalmente aparecerá el resultado.
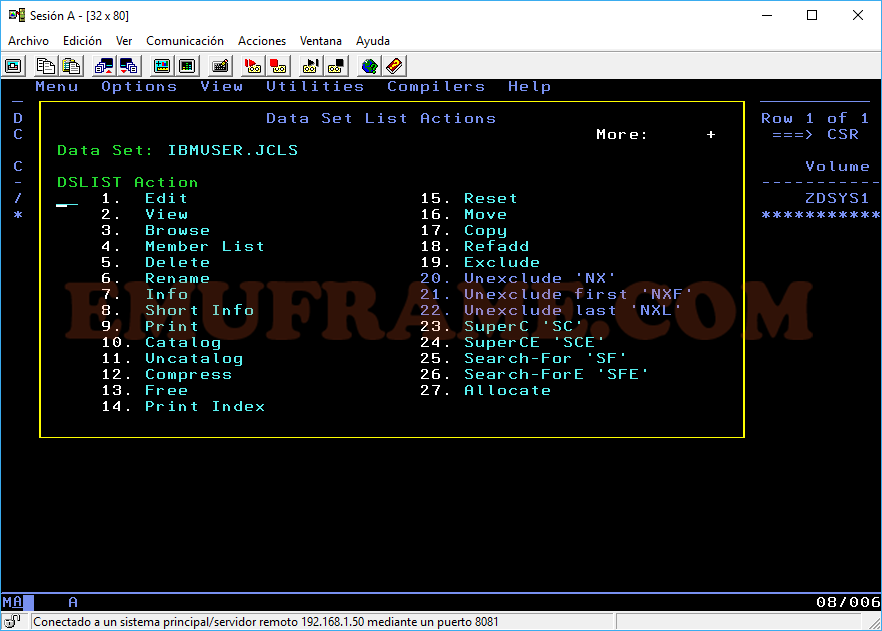
Cuando tenemos un listado de datasets, podemos realizar varias acciones sobre ellos.
B -> Accedemos en modo Browse. No permite modificarlo.
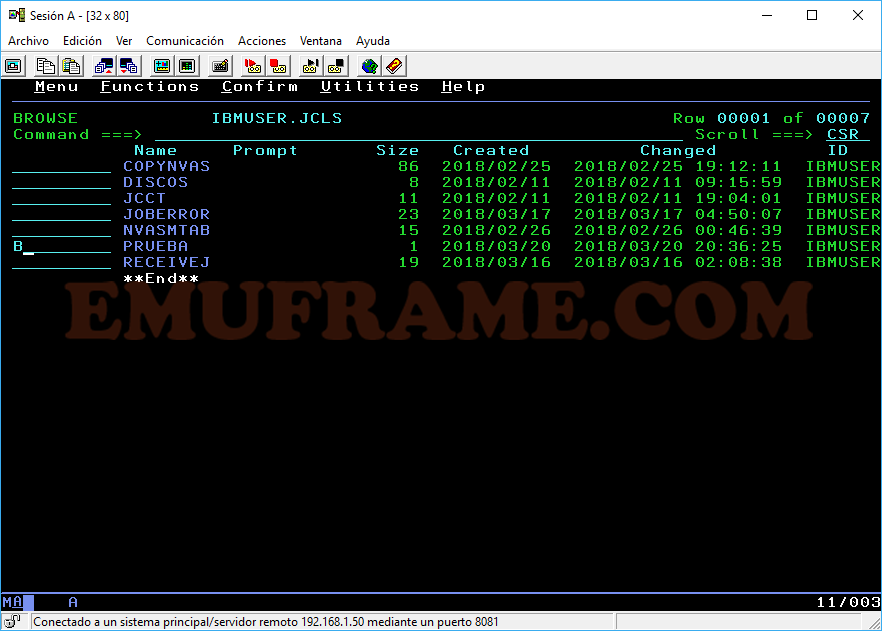
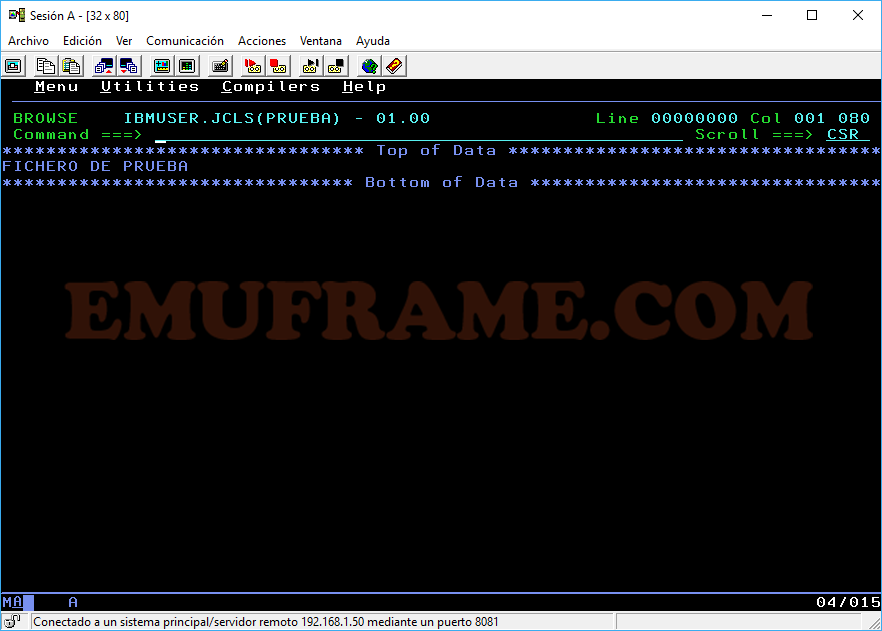
V -> Accedemos en modo View. Permite modificarlo, pero no podemos salvarlo.
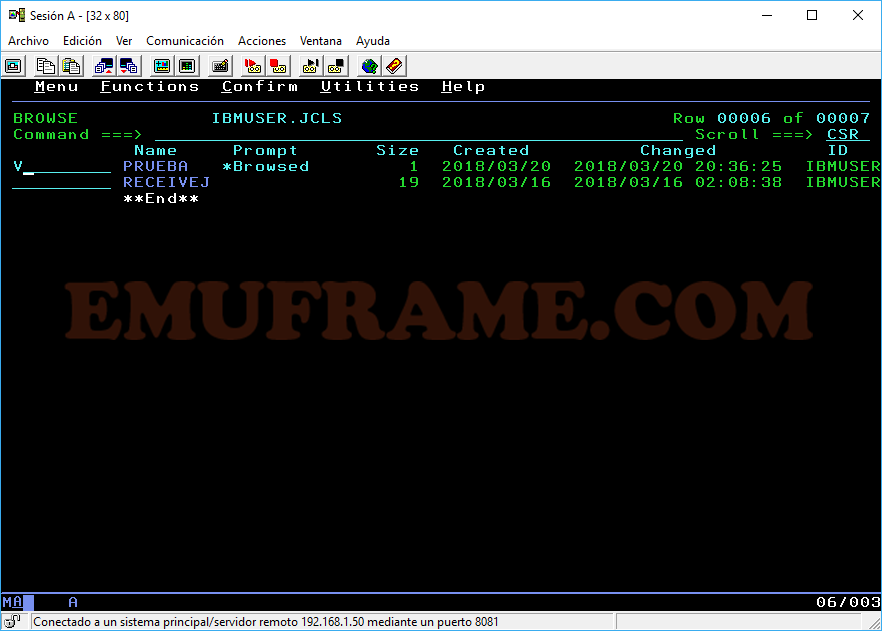
E -> Accedemos en modo Edit. Permite modificar y guardar.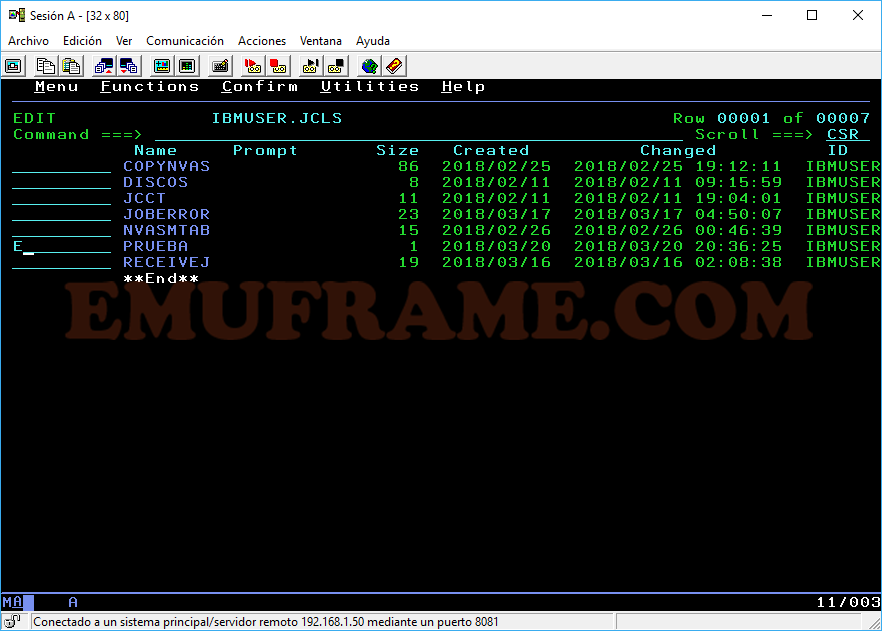
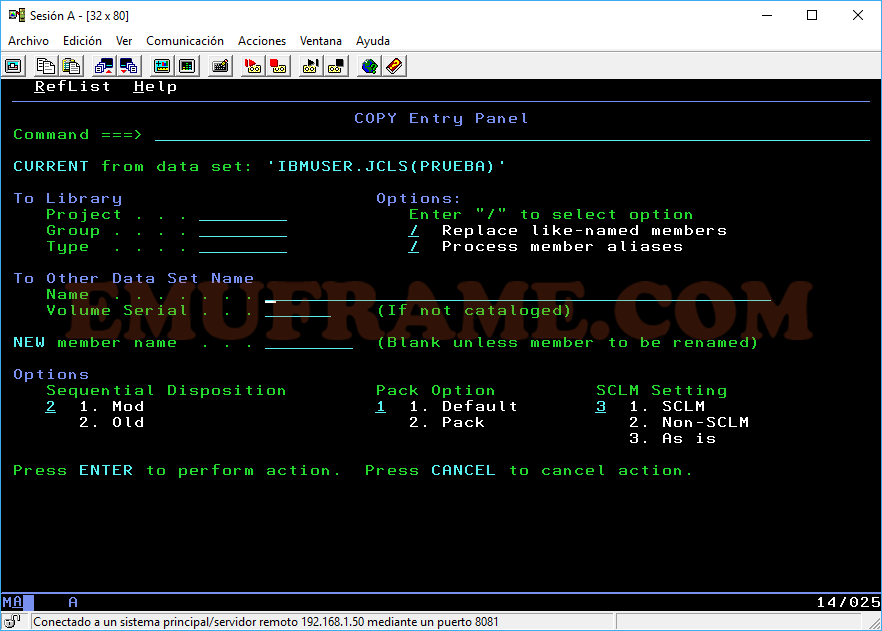
C -> Si se da a nivel de dataset, lo cataloga si está descatalogado. Si se da a nivel de miembro, copia el miembro. Si queremos copiar un dataset, tendremos que usar la opción CO
A nivel de dataset.
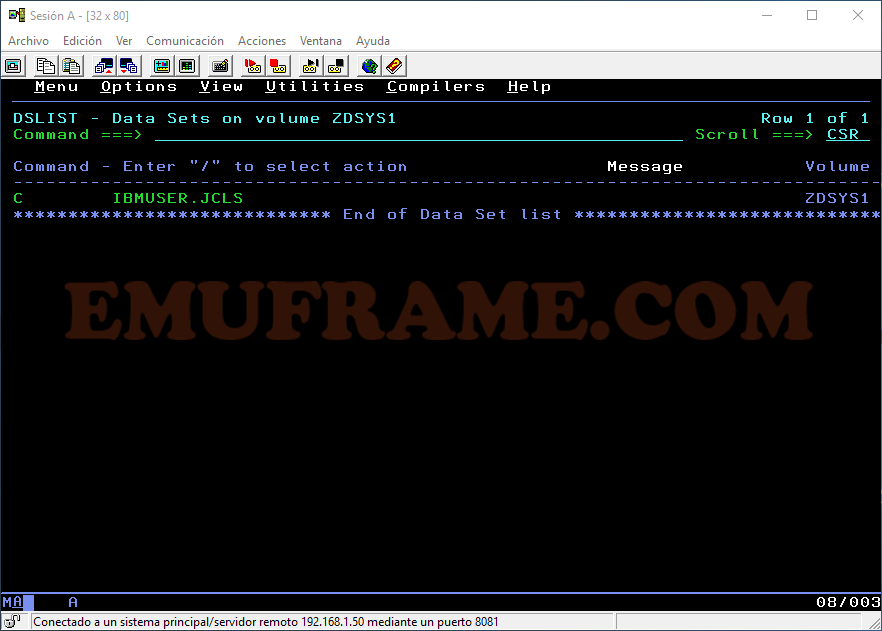
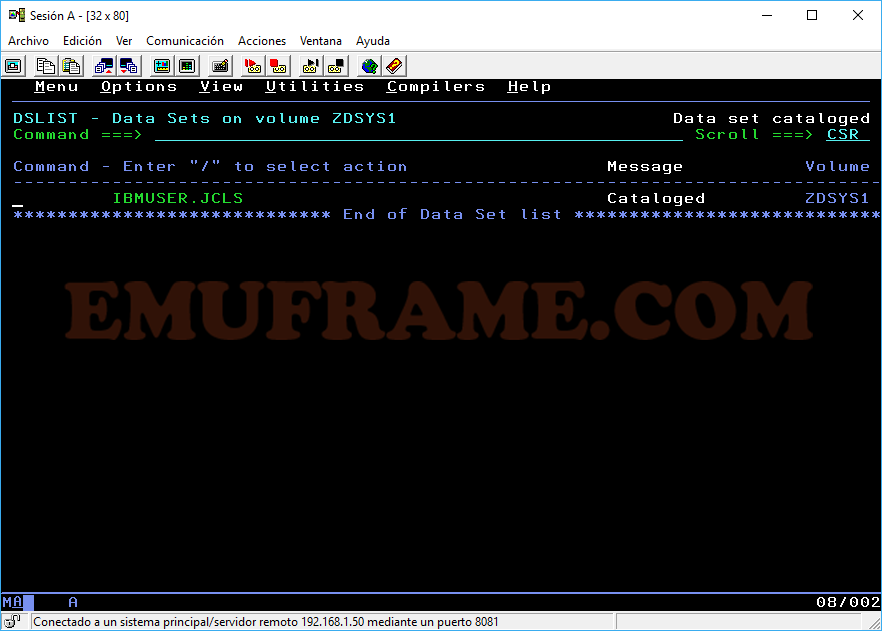
A nivel de miembro.
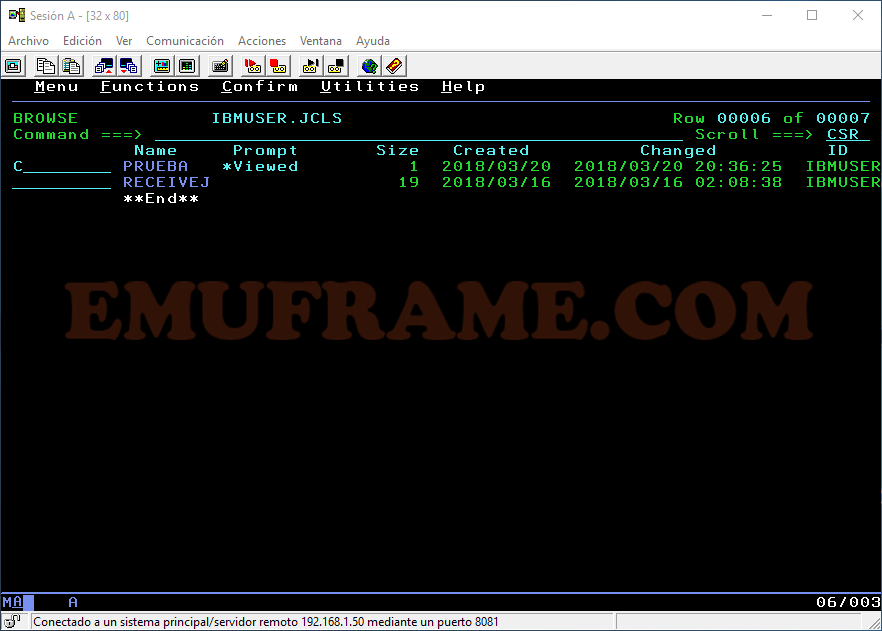
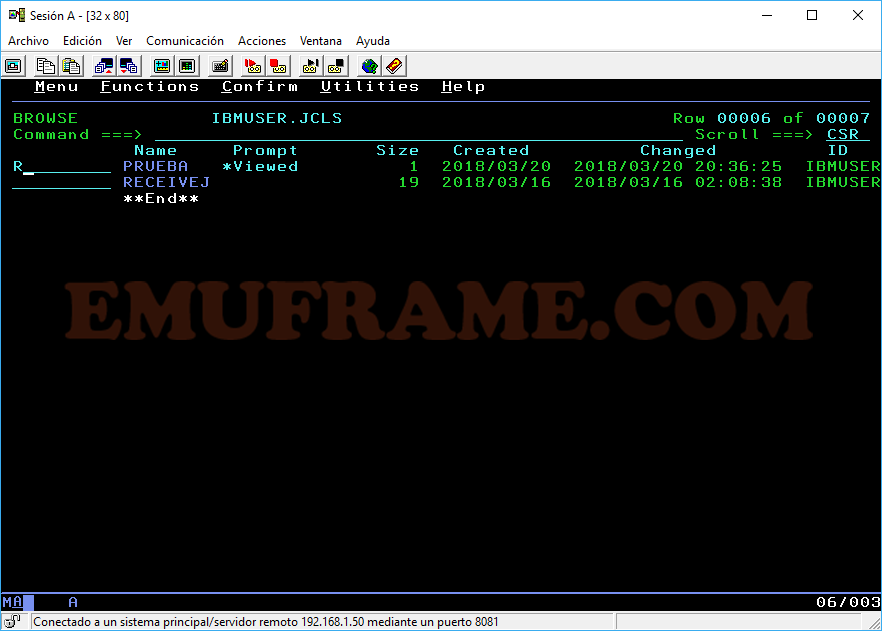
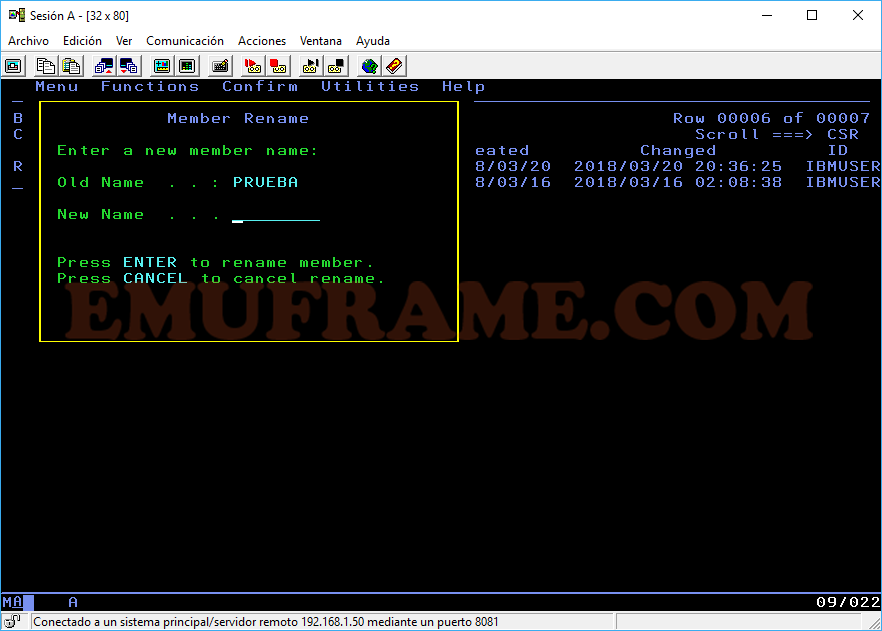
R -> Renombramos el datset o un miembro.
D -> Borramos el fichero y lo descatalogamos. Si borramos una librería particionada, borraremos todos los miembros que contiene. Para borrar un miembro únicamente, entraremos en la librería con el comando B, V o E y usaremos el comando “D” sobre el miembro correspondiente.
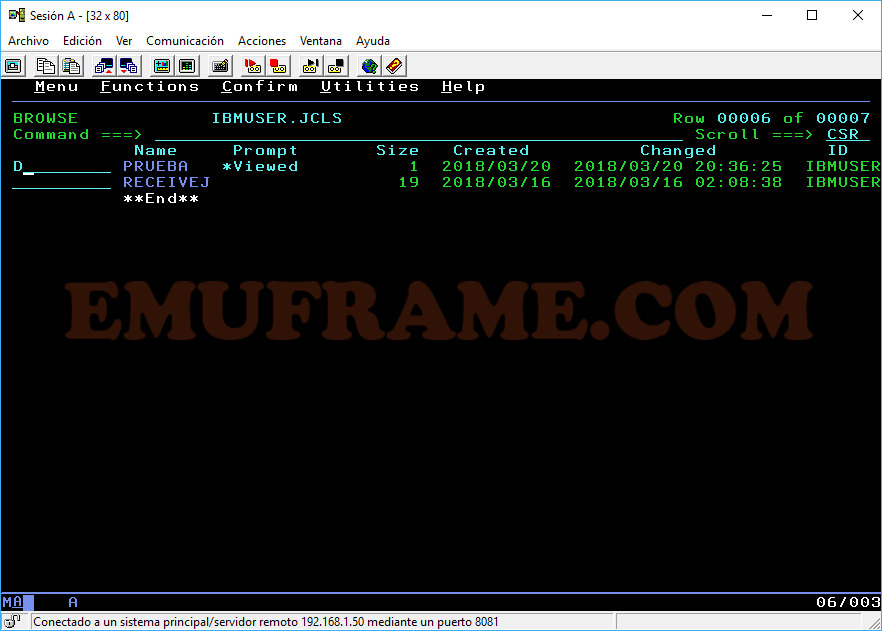
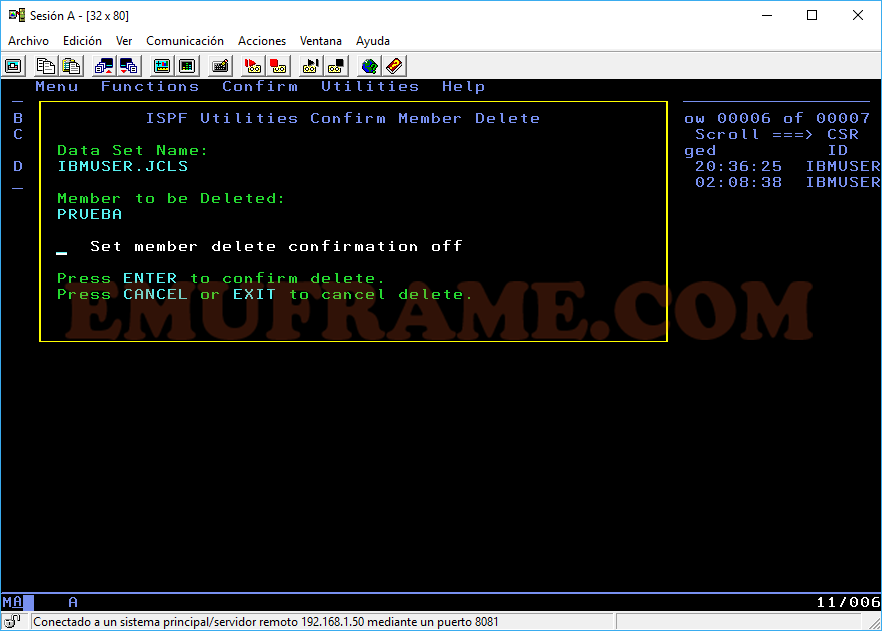
U -> Descatalogamos el fichero, pero no lo borramos. Seguirá existiendo en el disco. No funciona a nivel de miembro.
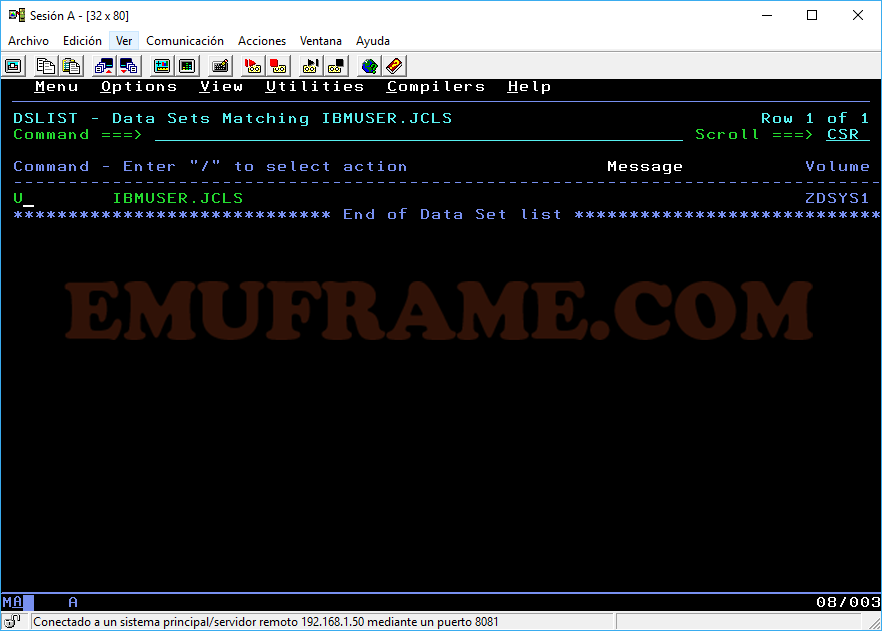
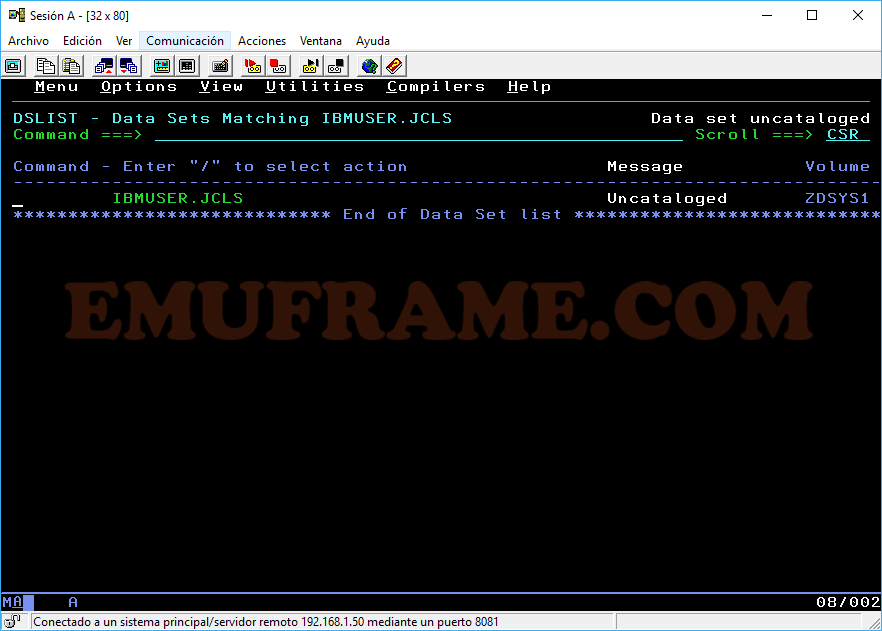
Z -> Sirve para comprimir librerías particionadas y poder liberar espacio. Hay que tener cuidado con esta opción porque se pueden corromper los datos.
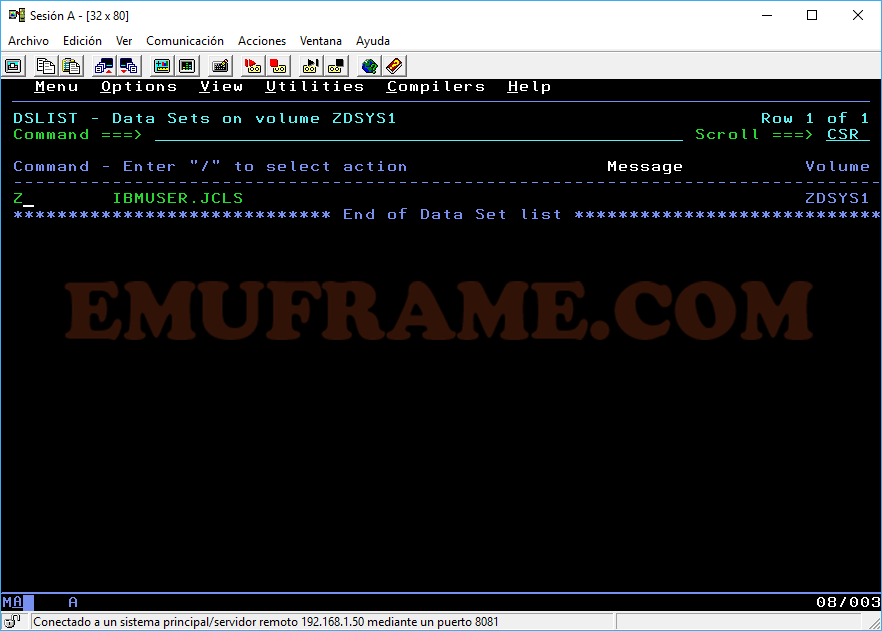
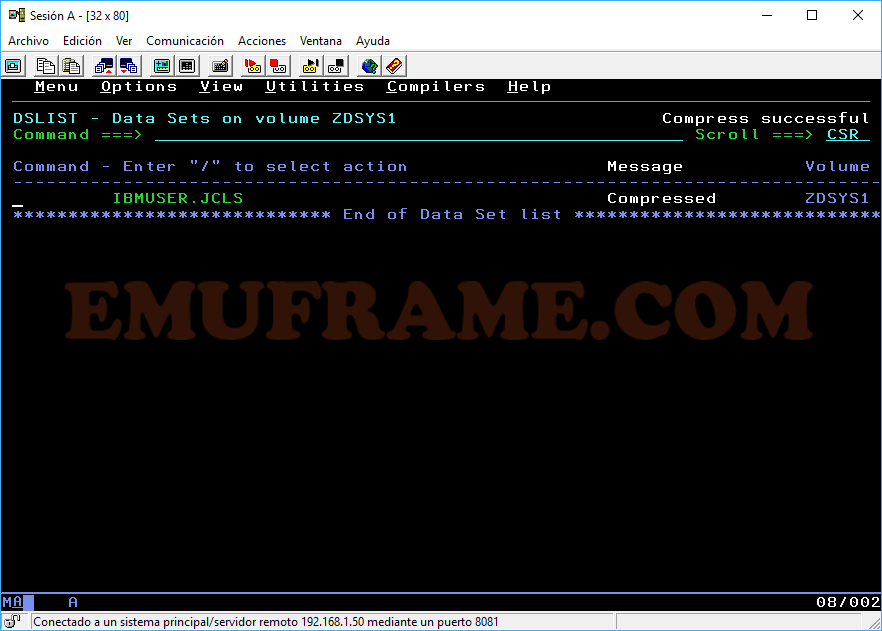
Estas suelen ser las opciones más habituales. En caso de querer ver otras opciones disponibles, pondremos una barra “/” en el dataset deseado.
Por ejemplo, aquí vemos que podemos copiar (opción 17) un dataset entero.
Si tenemos una lista de datasets y queremos buscar cuál de ellos tiene un miembro concreto, pondremos “MEMBER nombre_miembro”.
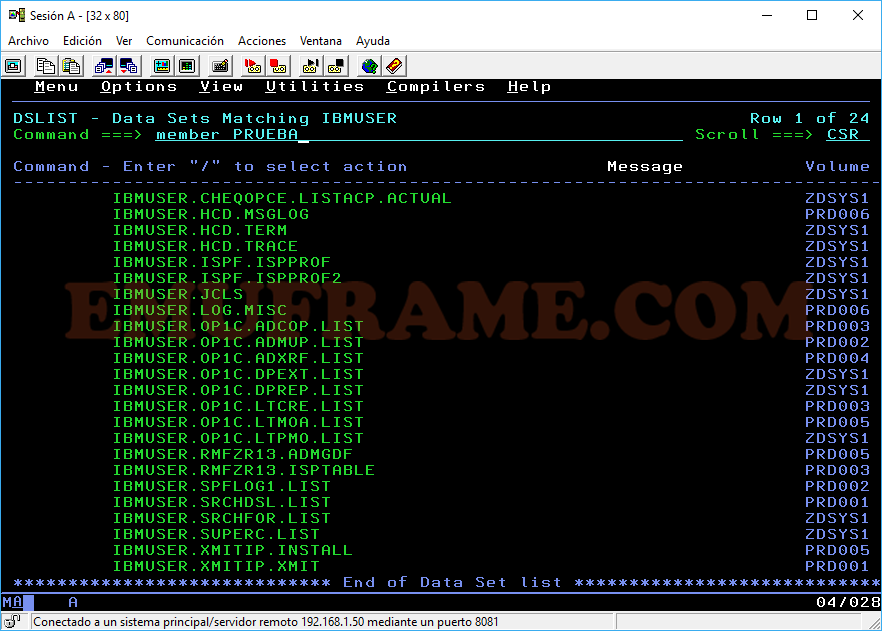
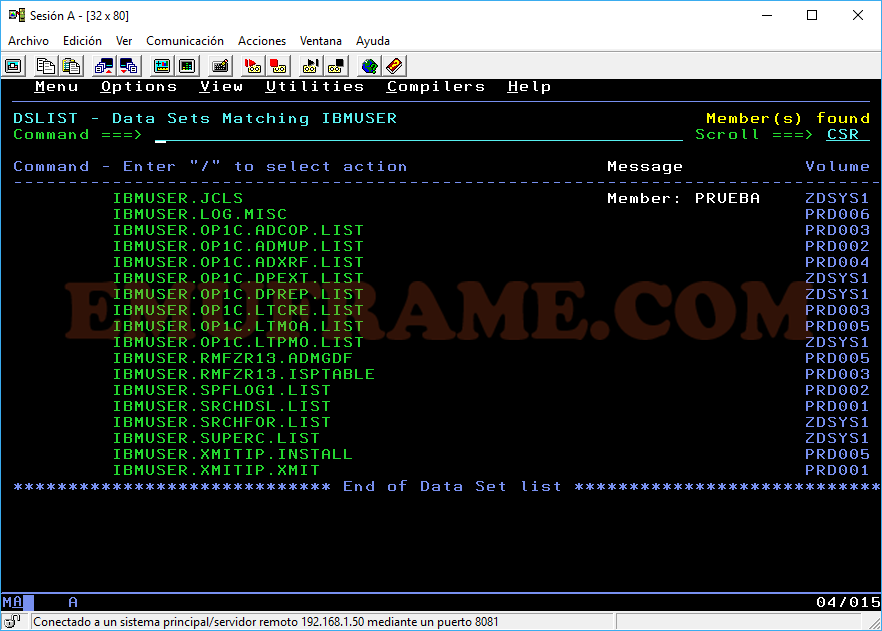
Si estamos dentro de una librería particionada y queremos buscar un miembro concreto, usaremos el comando FIND (F nombre_miembro) o el comando LOCATE (L nombre_miembro), para encontrarlo.
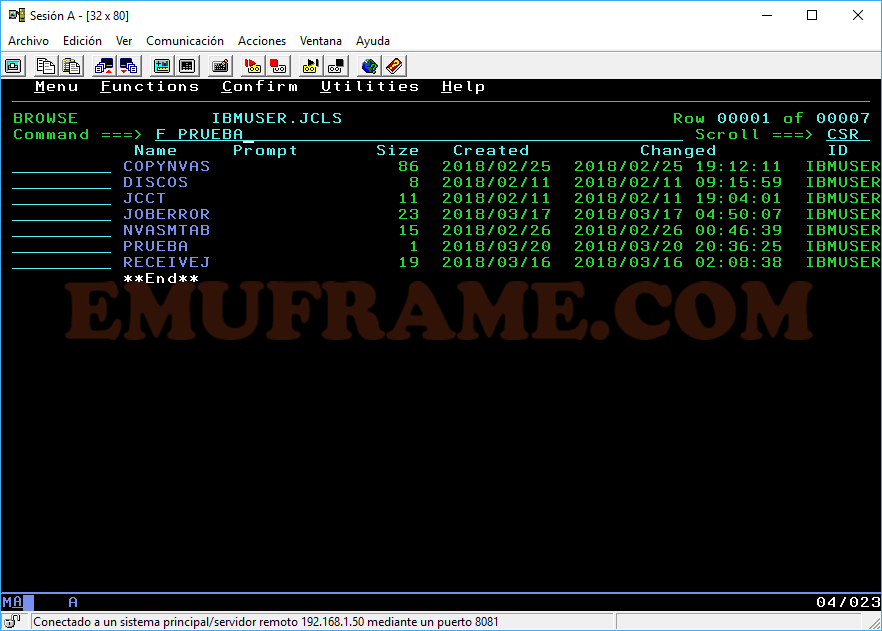
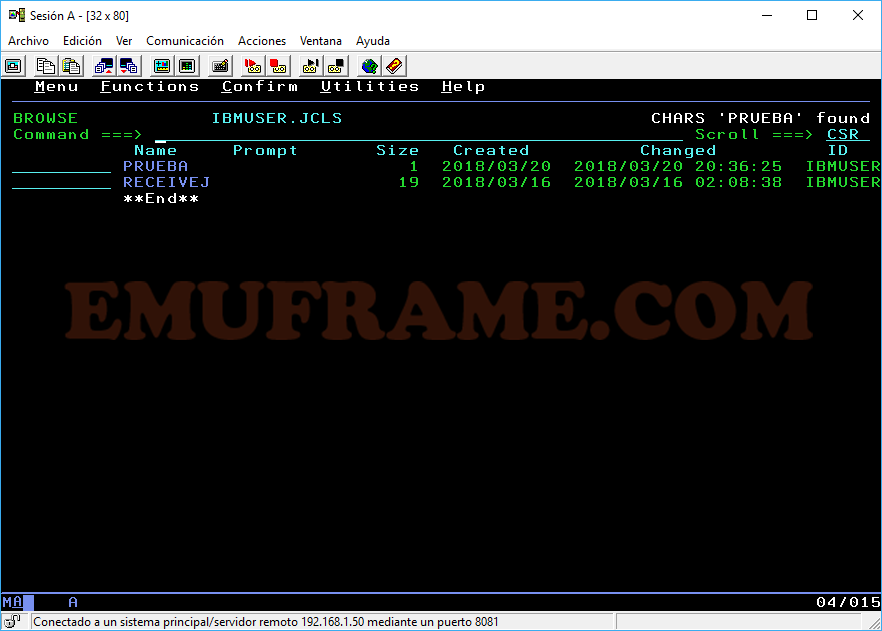
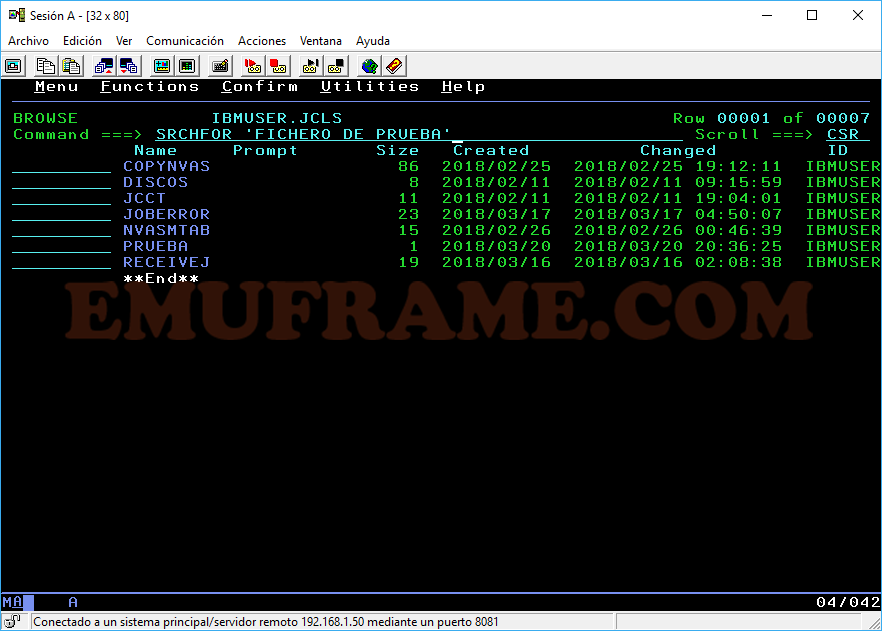
Si queremos buscar si un texto concreto se encuentra dentro de algún miembro, usaremos el comando SRCHFOR ‘texto’.
Por ejemplo: SRCHFOR ‘FICHERO DE PRUEBA’
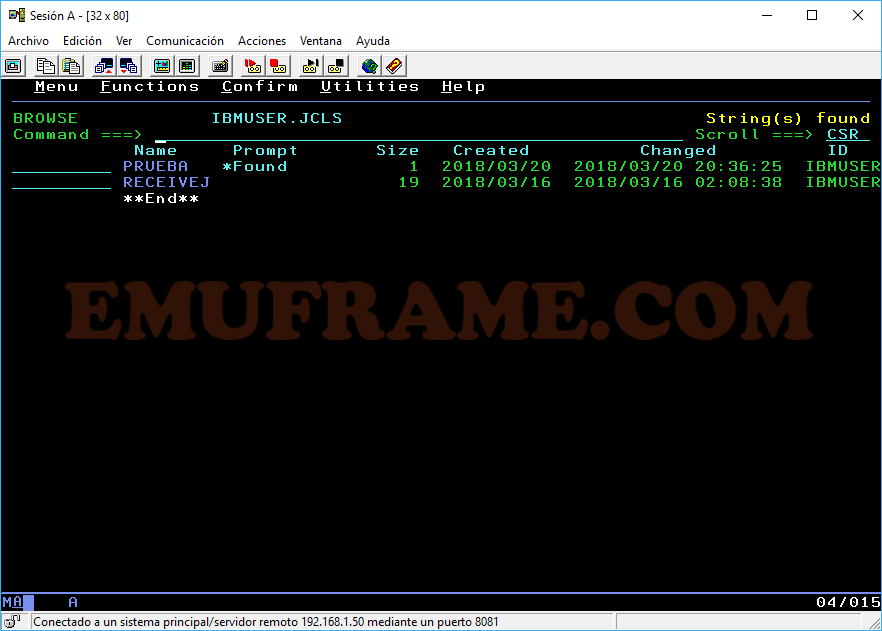
Nos aparecerá un mensaje indicando “String found” y el miembro o miembros que tienen ese texto en su interior.
Hasta aquí hemos visto cómo interactuar con los paneles de ISPF y algunas opciones más habituales.
En futuras entradas, veremos los tipos de datasets y cómo crearlos, cómo utilizar el editor de ISPF, los parámetros de los JCL, etc.